
topdown equivalent metrics for AMD Zen?
Intel processors provide a useful set of performance counters for doing topdown analysis, particularly at the first topdown level. This first level asks questions in the following hierarchy:
Is a Uop dispatched?
If yes, is it retired?
If yes --> retire
If no --> bad speculation
If no, is it stalled in the front end?
If yes --> front end stall
If no --> backend stall
Looking over the AMD Open Source register reference I don’t quite see the same equivalent registers to make these same choices – particularly when also looking at the microarchitectural diagram for a Zen processor.
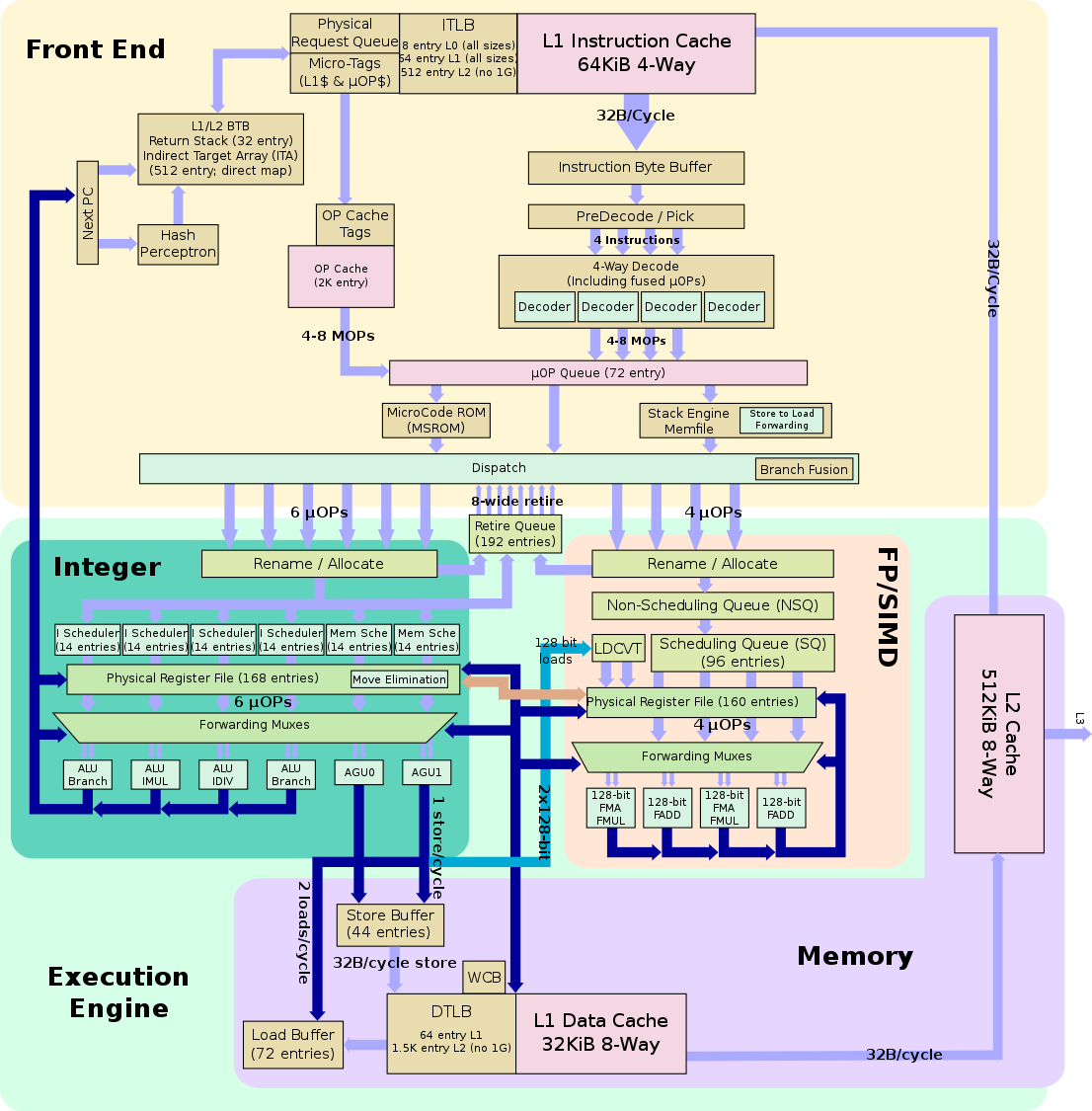{kind=link}
Here is what I see so far
- There is a counter for retired uops and so, I can calculate a percentage for the “retire” category above.
- I can’t find an equivalent counter for the number of uops dispatched. Instead some counters are either speculative and others are not but no overall number/percentage of how much is speculated and then not retired. On the Intel processor, this category has both branch misses and machine clears when the pipeline gets flushed. AMD Zen does at least have branch instructions and branch misses, so I can calculate this rate.
- The decoder has only a single event “dynamic dispatch stall cycles 0” that says “cycles where a dispatch group is valid but does not get dispatched due to a token stall”. Trying this one doesn’t seem to give a high enough percentage of the total cycles with such stalls.
- The instruction cache has a counter for instruction pipe stalls and two reasons: “instruction cache pipeline was stalled due to upstream not providing fetch addresses quickly” and “instruction cache pipeline was stalled during this clock cycle due to downstream queues being full”. At first blush this looks perhaps related to pipeline bubbles with either a frontend or backend cause. However, items I observe: the micro-op cache is after this stage and sanity checking examples doesn’t quite give me ratios that might match a similar Intel e.g. stream isn’t all waiting on backend
- Linux does have a /sys/devices/cpu/events/stalled-cycles-frontend and /sys/devices/cpu/events/stalled-cycles-backend files and these are reported by perf. However, I’ve recorded these for most benchmarks I’ve analyzed and they seem a bit random. Furthermore the event numbers 0xd0 and 0xd1 seem to match “retired conditional branch instructions” so there might be a chance this isn’t really maintained by AMD
For now, I’ve measured the IC/DE counters and print these as well as the uops. Following is an example for openssl:
ipc 1.112 retire 1.331 stall frontend (IC) 0.001 stall backend (IC) 0.251 stall (DE) 0.251
Here is what perf tells me including stalled cycles:
Performance counter stats for 'phoronix-test-suite batch-run openssl':
961681.830982 task-clock (msec) # 14.726 CPUs utilized
92,311 context-switches # 0.096 K/sec
163 cpu-migrations # 0.000 K/sec
67,142 page-faults # 0.070 K/sec
3,064,338,192,828 cycles # 3.186 GHz (83.34%)
2,661,073,645 stalled-cycles-frontend # 0.09% frontend cycles idle (83.32%)
116,196,691,350 stalled-cycles-backend # 3.79% backend cycles idle (83.32%)
3,421,037,597,123 instructions # 1.12 insn per cycle
# 0.03 stalled cycles per insn (83.33%)
133,627,301,522 branches # 138.952 M/sec (83.34%)
1,062,038,117 branch-misses # 0.79% of all branches (83.35%)
Here is the equivalent information on Haswell from the topdown tool
retire 0.922 ms_uops 0.001 speculation 0.006 branch_misses 97.63% machine_clears 2.37% frontend 0.066 idq_uops_delivered_0 0.005 icache_stall 0.000 itlb_misses 0.000 idq_uops_delivered_1 0.015 idq_uops_delivered_2 0.028 idq_uops_delivered_3 0.083 dsb_ops 92.68% backend 0.006 resource_stalls.sb 0.000 stalls_ldm_pending 0.117 l2_refs 0.000 l2_misses 0.000 l2_miss_ratio 27.15% l3_refs 0.000 l3_misses 0.000 l3_miss_ratio 12.89%
There isn’t a huge correlation here for Intel vs AMD where Intel mostly says a very high retirement rate (92%) and AMD says (1.331 uops/cycle) retire.
What I think I’ll do is first see if I can find some correlation on the equivalent uops retired and various stall metrics that makes some sense for the equivalent AMD workloads. If not, I’ll rely on Intel to roughly characterize the first level top down and then instead have the lower level counters by rough subsystem (e.g. branch miss performance, cache performance, …).
Comments
topdown equivalent metrics for AMD Zen? — No Comments
HTML tags allowed in your comment: <a href="" title=""> <abbr title=""> <acronym title=""> <b> <blockquote cite=""> <cite> <code> <del datetime=""> <em> <i> <q cite=""> <s> <strike> <strong>