
Blender is an open-source 3D creation software project. This test is of Blender’s Cycles benchmark with various sample files. GPU computing via OpenCL or CUDA is supported
The blender workload has five input files and three modes: CPU-Only, OpenCL and CUDA. Following are the elapsed time in seconds I see on my Intel and AMD systems for CPU-only mode. The Phoronix article and workloads page include only Barbershop. However, my analysis below uses all five input files.
Runtimes are considerably longer than for other Phoronix workloads. My AMD box continues to get scores roughly twice of my Intel box.
Intel AMD
BMW27 544.61 289.46
Classroom 1302.18 628.91
Fishy Cat 786.25 408.10
Barbershop 2635.12 1468.05
Pabellon Barcelona 1587.06 804.58
Metrics (Intel) - phoronix/blender
Metrics for all five workloads separately
sh - pid 520 // BMW27 On_CPU 0.996 On_Core 7.965 IPC 0.929 Retire 0.480 (48.0%) FrontEnd 0.205 (20.5%) Spec 0.086 (8.6%) Backend 0.229 (22.9%) Elapsed 549.33 Procs 56 Minflt 178840 Majflt 0 Utime 4374.90 (100.0%) Stime 0.26 (0.0%) Start 332948.28 Finish 333497.61 sh - pid 585 // Classroom On_CPU 0.999 On_Core 7.989 IPC 1.029 Retire 0.536 (53.6%) FrontEnd 0.234 (23.4%) Spec 0.072 (7.2%) Backend 0.158 (15.8%) Elapsed 1308.55 Procs 48 Minflt 188838 Majflt 0 Utime 10452.72 (100.0%) Stime 0.65 (0.0%) Start 333505.73 Finish 334814.28 sh - pid 692 // Fishy Cat On_CPU 0.995 On_Core 7.957 IPC 0.995 Retire 0.514 (51.4%) FrontEnd 0.182 (18.2%) Spec 0.112 (11.2%) Backend 0.193 (19.3%) Elapsed 790.29 Procs 48 Minflt 647075 Majflt 0 Utime 6287.66 (100.0%) Stime 0.88 (0.0%) Start 334822.41 Finish 335612.70 sh - pid 795 // Barbershop On_CPU 0.990 On_Core 7.923 IPC 0.800 Retire 0.413 (41.3%) FrontEnd 0.206 (20.6%) Spec 0.119 (11.9%) Backend 0.262 (26.2%) Elapsed 2631.79 Procs 69 Minflt 2845658 Majflt 0 Utime 20848.75 (100.0%) Stime 4.09 (0.0%) Start 335620.95 Finish 338252.74 sh - pid 1033 // Pabellon Barcelona On_CPU 0.999 On_Core 7.989 IPC 0.868 Retire 0.449 (44.9%) FrontEnd 0.193 (19.3%) Spec 0.110 (11.0%) Backend 0.248 (24.8%) Elapsed 1597.22 Procs 63 Minflt 144019 Majflt 0 Utime 12759.58 (100.0%) Stime 1.07 (0.0%) Start 338260.86 Finish 339858.08
A few things to note: first the On_CPU numbers are extremely high so the workload remains scheduled on the CPU at almost 100%. Second, the retiring percentage is slightly lower with front end and back end stalls perhaps contributing similar and wasted speculation also slightly higher than average. The IPC varies slightly by input files.
The resource chart below is also consistent with 100% On_CPU as number of involuntary context switches is low.
utime: 54469.605827 stime: 6.352188 maxrss: 7015K minflt: 4068215 majflt: 5 nswap: 0 inblock: 144704 oublock: 10904 msgsnd: 0 msgrcv: 0 nsignals: 0 nvcsw: 20559 nivcsw: 439295
Metrics (AMD) - phoronix/blender
Metrics for all five workloads separately
sh - pid 21985 // BMW27 On_CPU 0.983 On_Core 15.723 IPC 0.973 FrontCyc 0.041 (4.1%) BackCyc 0.082 (8.2%) Elapsed 291.18 Procs 101 Minflt 189299 Majflt 0 Utime 4577.98 (100.0%) Stime 0.16 (0.0%) Start 306221.12 Finish 306512.30 sh - pid 22099 // Classroom On_CPU 0.996 On_Core 15.934 IPC 1.164 FrontCyc 0.048 (4.8%) BackCyc 0.075 (7.5%) Elapsed 630.14 Procs 85 Minflt 195835 Majflt 0 Utime 10040.15 (100.0%) Stime 0.30 (0.0%) Start 306520.42 Finish 307150.56 sh - pid 22242 // Fishy Cat On_CPU 0.988 On_Core 15.809 IPC 1.060 FrontCyc 0.051 (5.1%) BackCyc 0.075 (7.5%) Elapsed 408.31 Procs 85 Minflt 656453 Majflt 0 Utime 6454.05 (100.0%) Stime 0.79 (0.0%) Start 307159.04 Finish 307567.35 sh - pid 22349 // Barbershop On_CPU 0.980 On_Core 15.684 IPC 0.794 FrontCyc 0.058 (5.8%) BackCyc 0.062 (6.2%) Elapsed 1472.31 Procs 130 Minflt 2862890 Majflt 0 Utime 23087.91 (100.0%) Stime 4.00 (0.0%) Start 307575.47 Finish 309047.78 sh - pid 22575 // Pabellon Barcelona On_CPU 0.996 On_Core 15.943 IPC 0.946 FrontCyc 0.049 (4.9%) BackCyc 0.074 (7.4%) Elapsed 804.45 Procs 131 Minflt 151736 Majflt 0 Utime 12825.16 (100.0%) Stime 0.32 (0.0%) Start 309056.05 Finish 309860.50
Process Tree - phoronix/blender
Process Tree
The process tree shows a similar pattern. Operations are spawned with two threads on each core. There are a few very small <1 second operations and in the middle one long-running operation for over 40 minutes. Below is the processtree for barbershop, but others are similar.
795) sh elapsed=2631.79 start=0.00 finish=2631.79
797) blender elapsed=2631.79 start=0.00 finish=2631.79
803) blender elapsed=0.18 start=0.00 finish=0.18
804) blender elapsed=0.15 start=0.02 finish=0.17
805) blender elapsed=0.15 start=0.02 finish=0.17
806) blender elapsed=0.15 start=0.02 finish=0.17
807) blender elapsed=0.15 start=0.02 finish=0.17
808) blender elapsed=0.15 start=0.02 finish=0.17
809) blender elapsed=0.15 start=0.02 finish=0.17
810) blender elapsed=0.15 start=0.02 finish=0.17
811) blender elapsed=0.15 start=0.02 finish=0.17
812) threaded-ml elapsed=0.00 start=0.05 finish=0.05
813) threaded-ml elapsed=0.12 start=0.05 finish=0.17
814) blender elapsed=0.12 start=0.05 finish=0.17
815) blender elapsed=0.00 start=0.05 finish=0.05
817) blender elapsed=0.02 start=0.14 finish=0.16
819) blender elapsed=0.02 start=0.14 finish=0.16
820) blender elapsed=0.02 start=0.14 finish=0.16
821) blender elapsed=0.02 start=0.14 finish=0.16
822) blender elapsed=0.02 start=0.14 finish=0.16
824) blender elapsed=0.02 start=0.14 finish=0.16
826) blender elapsed=0.02 start=0.14 finish=0.16
827) blender elapsed=2631.42 start=0.18 finish=2631.60
829) blender elapsed=2631.41 start=0.19 finish=2631.60
830) blender elapsed=2631.41 start=0.19 finish=2631.60
832) blender elapsed=2631.41 start=0.19 finish=2631.60
833) blender elapsed=2631.41 start=0.19 finish=2631.60
834) blender elapsed=2631.41 start=0.19 finish=2631.60
835) blender elapsed=2631.41 start=0.19 finish=2631.60
836) blender elapsed=2631.41 start=0.19 finish=2631.60
837) blender elapsed=2631.41 start=0.19 finish=2631.60
838) blender elapsed=2630.89 start=0.71 finish=2631.60
842) blender elapsed=2630.89 start=0.71 finish=2631.60
843) blender elapsed=2630.89 start=0.71 finish=2631.60
844) blender elapsed=2630.89 start=0.71 finish=2631.60
846) blender elapsed=2630.89 start=0.71 finish=2631.60
847) blender elapsed=2630.89 start=0.71 finish=2631.60
848) blender elapsed=2630.89 start=0.71 finish=2631.60
849) blender elapsed=2630.61 start=0.99 finish=2631.60
850) blender elapsed=2630.61 start=0.99 finish=2631.60
851) blender elapsed=2630.61 start=0.99 finish=2631.60
852) blender elapsed=2630.61 start=0.99 finish=2631.60
853) blender elapsed=2630.61 start=0.99 finish=2631.60
854) blender elapsed=2630.60 start=1.00 finish=2631.60
855) blender elapsed=2630.60 start=1.00 finish=2631.60
859) blender elapsed=2630.25 start=1.35 finish=2631.60
860) blender elapsed=2630.25 start=1.35 finish=2631.60
864) blender elapsed=2630.25 start=1.35 finish=2631.60
865) blender elapsed=2630.25 start=1.35 finish=2631.60
866) blender elapsed=2630.25 start=1.35 finish=2631.60
869) blender elapsed=2630.25 start=1.35 finish=2631.60
870) blender elapsed=2630.25 start=1.35 finish=2631.60
871) blender elapsed=2629.35 start=2.12 finish=2631.47
 About this graph
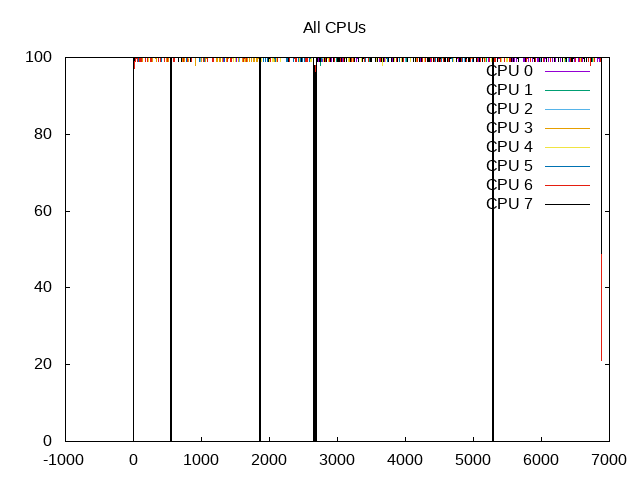
About this graph
Overall CPU usage almost at 100% with gaps between workloads visible as well as their relative durations.
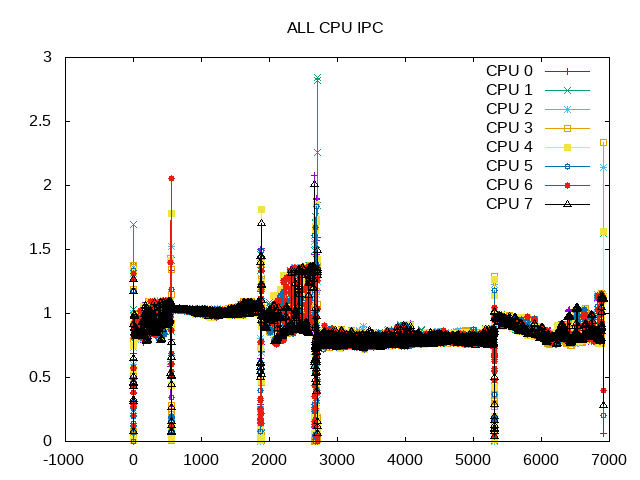
IPC numbers are slightly more heavy, partially because there are so many data points. However, it does show the third workload slightly more chaotic and the second and fourth ones more similar.
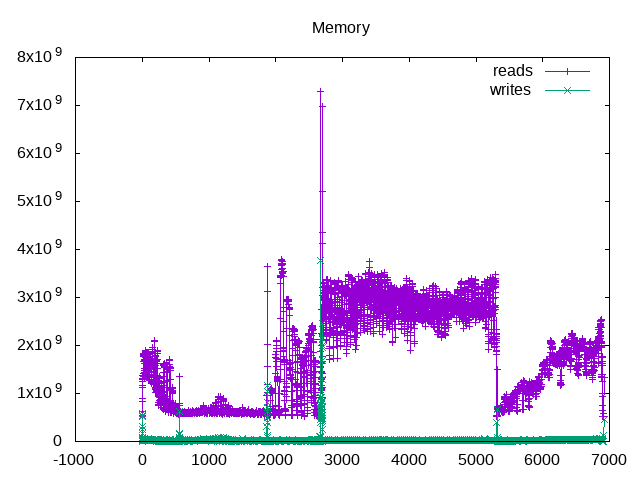
Somewhat more memory read traffic in the third workload correlates with a higher IPC. However, it will also be useful to correlate this “top down” with memory stall measurements.
 About this graph
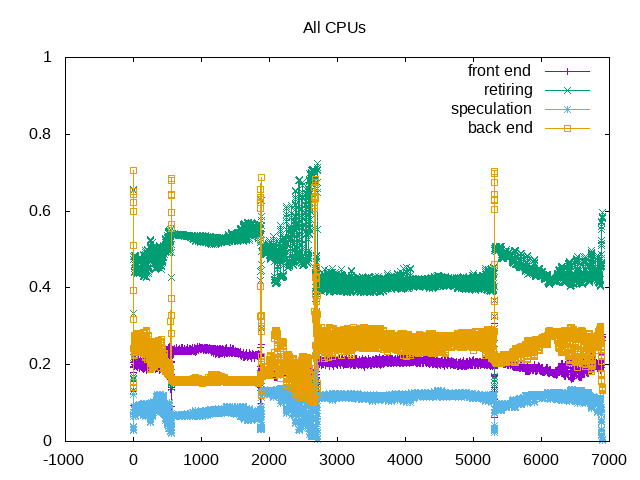
About this graph
Topdown metrics show varying amounts of backend, as well as correlation with memory traffic.
Next steps: Drill down on next level metrics, e.g. how much of backend is memory-bound vs. core-bound. At lower priority, anything we can tell about the speculation misses?